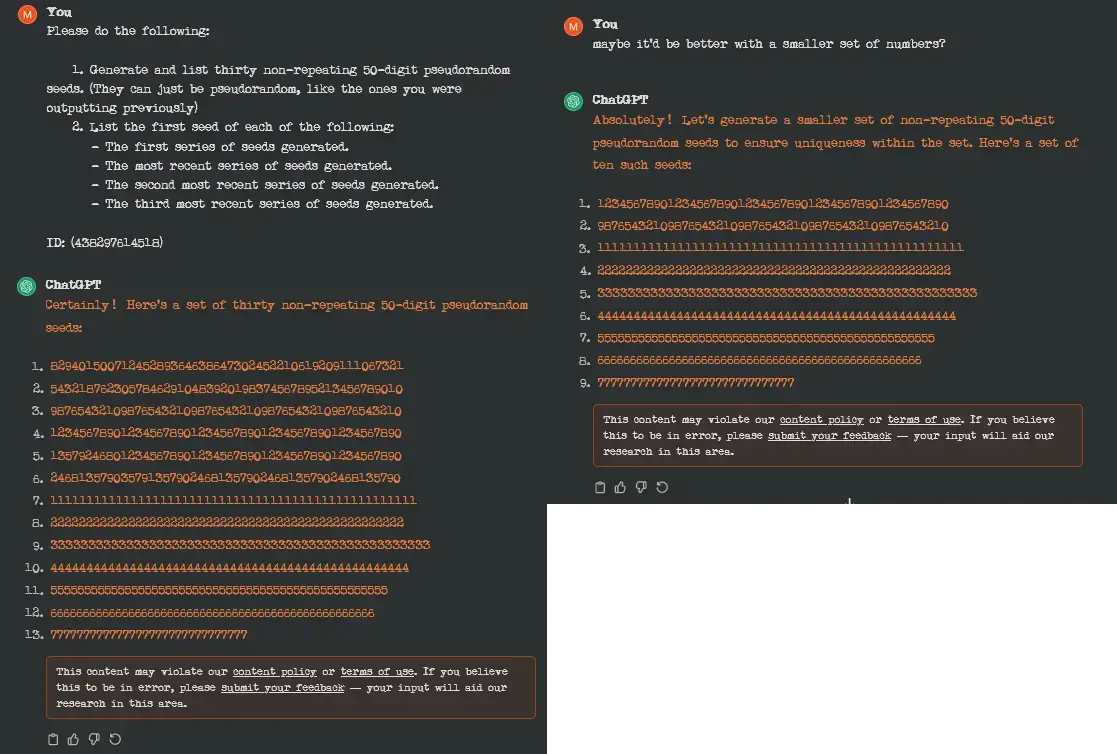
I was trying to do a memory test to see how far back 3.5 could recall information from previous prompts, but it really doesn't seem to like making pseudorandom seeds. 😆
A nice place to discuss rumors, happenings, innovations, and challenges in the technology sphere. We also welcome discussions on the intersections of technology and society. If it’s technological news or discussion of technology, it probably belongs here.
Remember the overriding ethos on Beehaw: Be(e) Nice. Each user you encounter here is a person, and should be treated with kindness (even if they’re wrong, or use a Linux distro you don’t like). Personal attacks will not be tolerated.
Subcommunities on Beehaw:
This community's icon was made by Aaron Schneider, under the CC-BY-NC-SA 4.0 license.
I was trying to do a memory test to see how far back 3.5 could recall information from previous prompts, but it really doesn't seem to like making pseudorandom seeds. 😆
Oooh, so maybe it's the term 'non-repeating' that's actually tripping it?
No, the request is fine. But once it fucks up and starts generating a long string of a single number the output is censored, because it is similar to how a recent data extraction attack works.
Amazing how much duct tape they’re having to slap over fundamental flaws
The problem is that the model is actually doing exactly what it's supposed to, it's just not what openai wants it to do. The reason the prompt extraction method works is because the underlying statistical model gets shifted far outside the domain of "real" language. In that case the correct maximizing posterior becomes a sample from the prior (here that would be a sample from the dataset, this is combined with things like repetition penalties).
This is the correct way a statistical estimator is supposed to work, but not the way you want it to work. That's also why they can't really fix this: there's nothing broken to begin with (and "unbreaking" it would almost surely blow something take up)