Hi everyone, I've been building my own log search server because I wasn't satisfied with any of the alternatives out there and wanted a project to learn rust with. It still needs a ton of work but wanted to share what I've built so far.
The repo is up here: https://codeberg.org/Kryesh/crystalline
and i've started putting together some documentation here: https://kryesh.codeberg.page/crystalline/
There's a lot of features I plan to add to it but I'm curious to hear what people think and if there's anything you'd like to see out of a project like this.
Some examples from my lab environment:
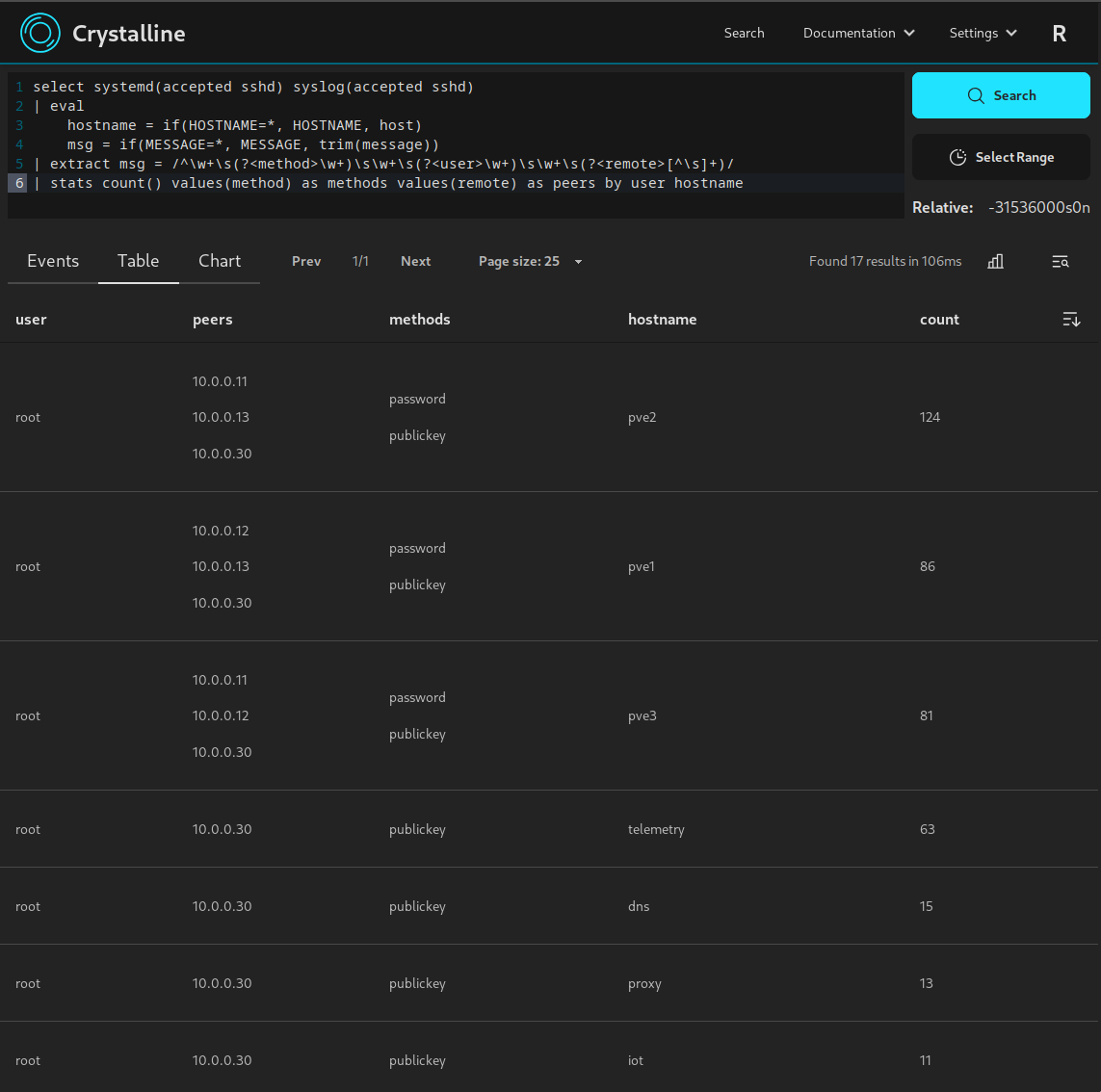
events view searching for SSH logins from systemd journals and syslog events:

counting raw event size for all indices:

performance is looking pretty decent so far, and it can be configured to not be too much of a resource hog depending on use case, some numbers from my test install:
- raw events ingested: ~52 million
- raw event size: ~40GB
- on disk size: ~5.8GB
Ram usage:
- not running searches ingesting 600MB-1GB per day it uses about 500MB of ram
- running the ssh search examples above brings it to about 600MB of ram while the search is running
- running last example search getting the size of all events (requires decompressing the entire event store) peaked at about 3.5GB of ram usage